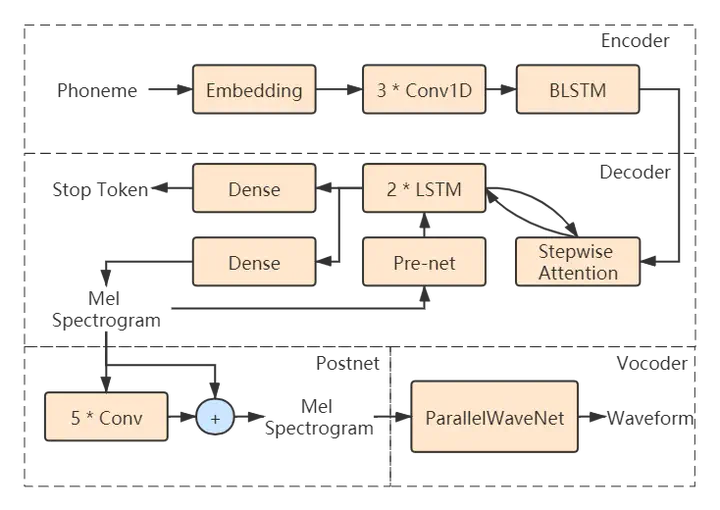
Abstract
End-to-end neural TTS has achieved excellent performance on reading style speech synthesis. However, it is still a challenge to build a high-quality conversational TTS due to the limitations of corpus and modeling capability. This study aims at building a conversational TTS for a voice agent under sequence to sequence modeling framework. We firstly construct a spontaneous conversational speech corpus well designed for the voice agent with a new recording scheme ensuring both recording quality and conversational speaking style. Secondly, we propose a conversation context-aware end-to-end TTS approach that employs an auxiliary encoder and a conversational context encoder to specifically reinforce the information about the current utterance and its context in a conversation as well. Experimental results show that the proposed approach produces more natural prosody in accordance with the conversational context, with significant preference gains at both utterance-level and conversation-level. Moreover, we find that the model has the ability to express some spontaneous behaviors like fillers and repeated words, which makes the conversational speaking style more realistic.