Towards High-Quality Neural TTS for Low-Resource Languages by Learning Compact Speech Representations
Abstract
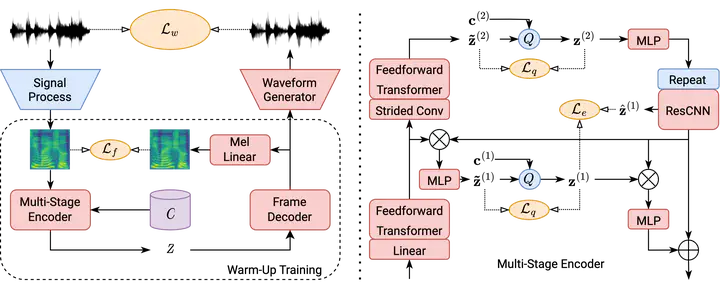
This paper aims to enhance low-resource TTS by reducing training data requirements using compact speech representations. A Multi-Stage Multi-Codebook (MSMC) VQ-GAN is trained to learn the representation, MSMCR, and decode it to waveforms. Subsequently, we train the multi-stage predictor to predict MSMCRs from the text for TTS synthesis. Moreover, we optimize the training strategy by leveraging more audio to learn MSMCRs better for low-resource languages. It selects audio from other languages using speaker similarity metric to augment the training set, and applies transfer learning to improve training quality. In MOS tests, the proposed system significantly outperforms FastSpeech and VITS in standard and low-resource scenarios, showing lower data requirements. The proposed training strategy effectively enhances MSMCRs on waveform reconstruction. It improves TTS performance further, which wins 77% votes in the preference test for the low-resource TTS with only 15 minutes of paired data.